How to annotate your website with linked data
April 14, 2019
A web for machines
The web was primarily designed to be accessed by humans equipped with web browsers. Search engines, through crawlers, make an extraordinary work to index all the HTML documents out there but the content of webpages remain mostly unintelligible to machines. This is because raw texts and media cannot be processed directly by machines. Advances in machine learning and AI makes it easier and easier to derive meaning from unstructured content (see Named Entity Recognition, speech recognition, computer vision) but there is still a long way to go. The semantic web, or web of data is framework for annotating documents (adding metadata) to the content of web pages using standards by the W3C. Given these annotations, machines may be able to extract entities/types and relations between those entities. This is a process of structuring unstructured data and making links between them. Tim Berneers Lee calls it « Linked Data ».
Connected together, all this data makes up a « knowledge graph ». This technology allows Google to display rich snippets on the right side of the screen when you make searches.
In his famous article The Semantic Web, Tim Berneers Lee envisions a world where intelligent web agents would be able to make the most of this data to perform complex tasks like booking appointments.
The agent promptly retrieved information about Mom’s prescribed treatment from the doctor’s agent, looked up several lists of providers, and checked for the ones in-plan for Mom’s insurance within a 20-mile radius of her home and with a rating of excellent or very good on trusted rating services. It then began trying to find a match between available appointment times (supplied by the agents of individual providers through their Web sites) and Pete’s and Lucy’s busy schedules.

Metadata tags
One of the easiest way to add structured data to a web page is through the HTML metadata tags. Metadata will not be displayed on the page but will help machines understand basic context about your web page. You can add the author, description, keywords, etc.
You can also add open graph tags that help most social media websites to integrate your page as part of their social graph. It allows Facebook for example to display an enriched media when you copy/paste the link of your website in a post.

RDF
RDF or Resource Description Framework is a set of specifications used to represent data on web pages. It uses the triple (subject, predicate, object) to represents knowledge.
Tim Berneers Lee is the inventor of the web
subject = Tim Berneers Lee, predicate = inventor, object = the web
In this framework, subject, predicate and object are HTTP URI’s so that you can follow up links and discover linked data. Vocabularies are used to uniquely identify concepts and relationships used to represent an area of concern (=ontologies). On my personal website I use schema.org.
Several serialization techniques and standards can be used, the most common being RDFa, JSON-LD, Turtle. I personnaly use JSON-LD on my website because I am familiar with JSON and it is the format recommended by Google for search engine optimization 1. You just have to add a <script> tag in the header of your webpage
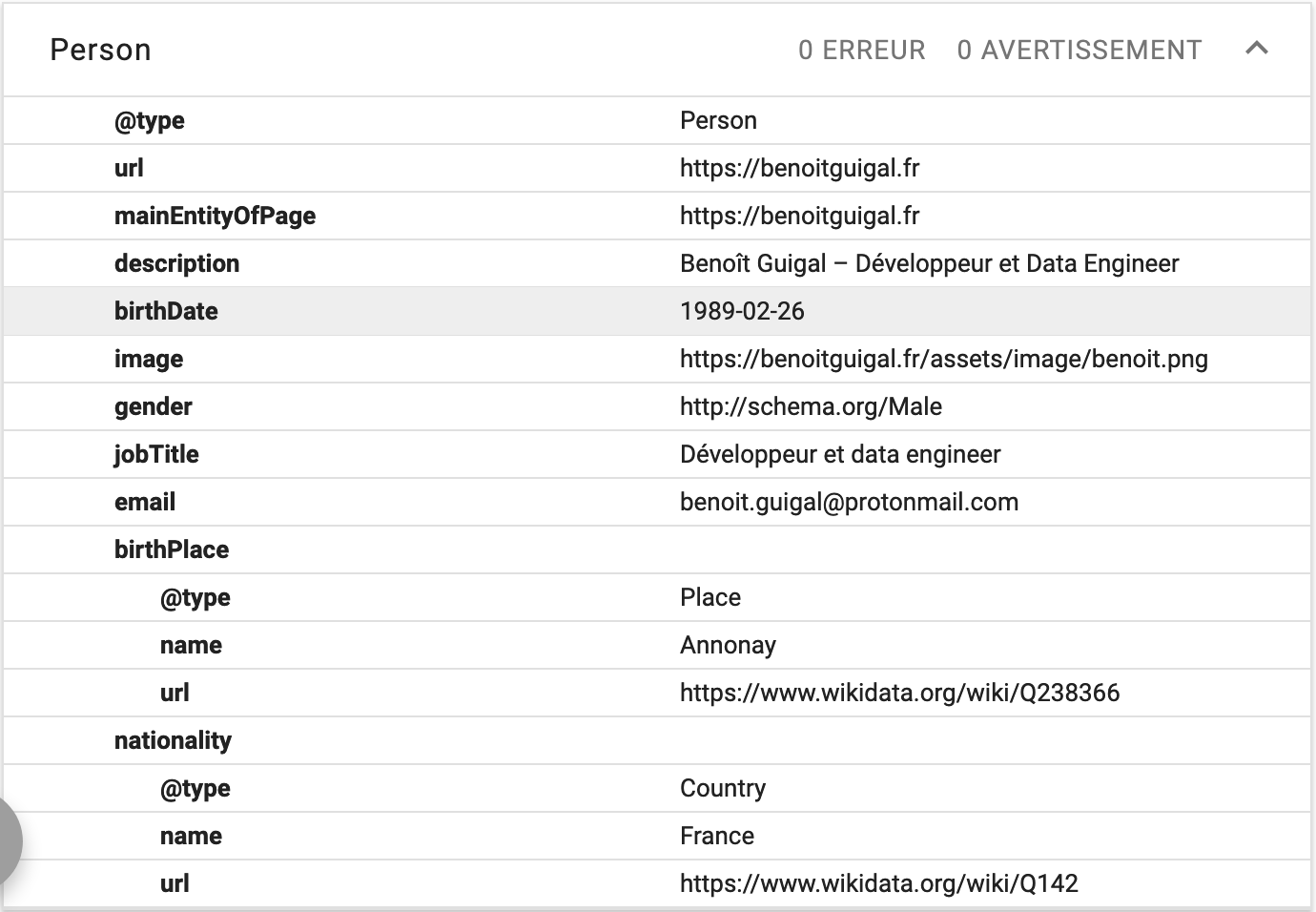
You can test how your linked data is parsed thanks to Google structured data testing tool. Below is how it looks for my website: